The multi-agent future just got real. Here's why it needs a trust layer at the database.
This week, Aakash Gupta posted about OpenClaw — the open-source orchestration framework that's turning heads in the agentic AI community. The demo is striking: you give OpenClaw a task, and it doesn't just execute. It architects a solution, spins up sub-agents to handle components, then manages those agents autonomously.
One developer, Naman Pandey, is building a system called Fella — a primary "CEO-type" agent that sits on top of 16 specialized sub-agents. Live knowledge bots. Automated standups. Push-based competitive intelligence. VOC reporting. Auto bug routing. Fella decides what to surface and what to handle silently. The rest runs in the background while the human sleeps.
Naman's words: "It's kind of like a CEO type model. I don't need to know all the details of everything going on."
This is the architectural pattern that separates what's coming from what came before. Copilots augment one human doing one task. Orchestration frameworks like OpenClaw spawn hierarchies of agents that delegate to each other, persist through restarts, and operate on schedules you set once and never touch again.
It's impressive. It's also terrifying — if you think about what's happening underneath.
The problem nobody's demo is showing you
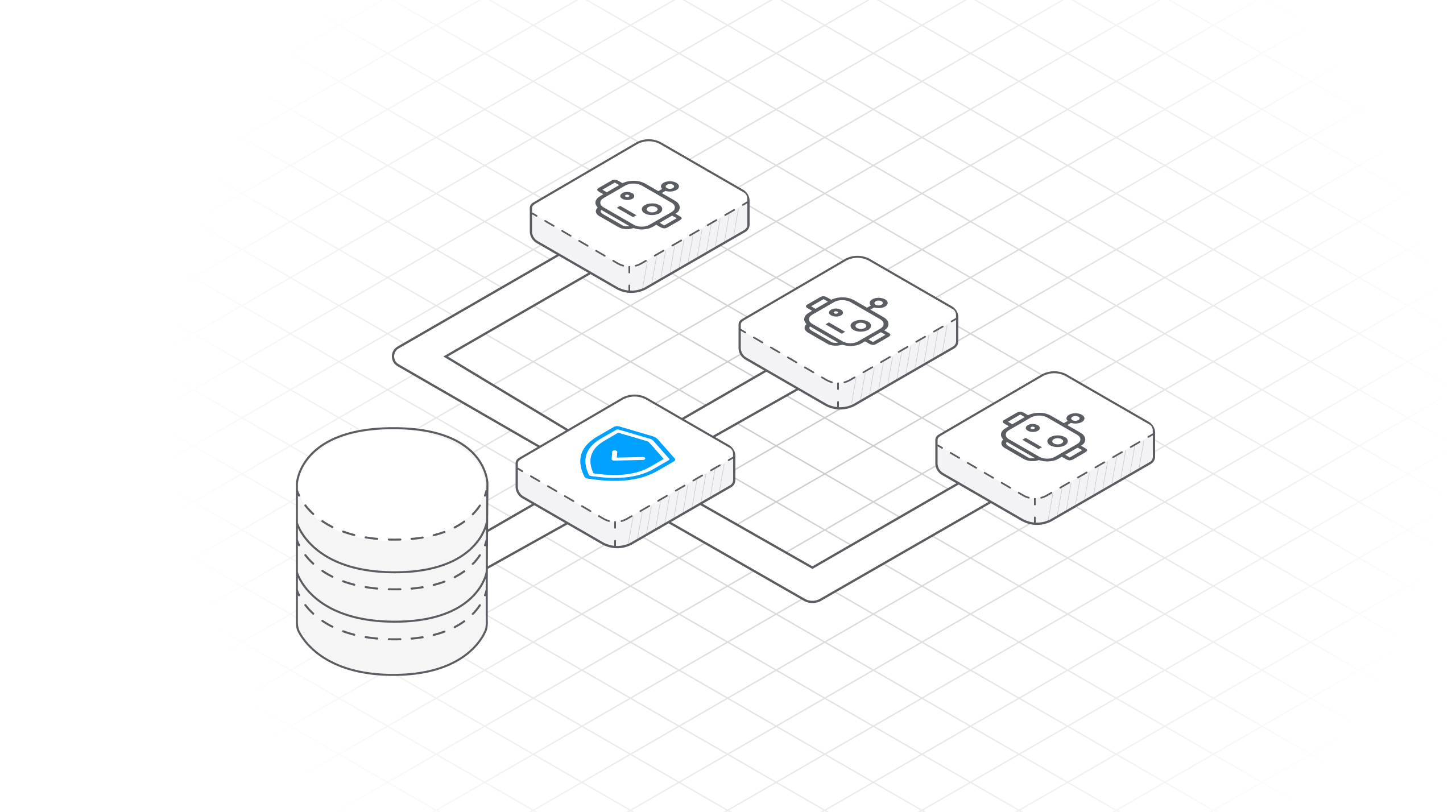
When one agent talks to your database, security is manageable. You can scope its access, review its queries, monitor its behavior. It's not that different from a human user with an API key.
When sixteen agents talk to your database — spawned dynamically, operating autonomously, sharing memory, accessing overlapping datasets across users, teams, and sessions — you have a fundamentally different problem.
Every sub-agent in a system like Fella needs access to some data. The competitive intelligence bot needs market signals. The VOC bot needs customer feedback. The bug routing agent needs error logs and engineering context. But none of them should see everything. The comp-intel bot has no business reading customer PII. The standup summarizer shouldn't access credentials stored for the smart-home integration.
In the current default architecture, most of these frameworks persist state in local Markdown files and SQLite. That works beautifully for a solo demo on a laptop. It does not work when you're running a hierarchy of autonomous agents for a real team, across real departments, with real compliance requirements.
The moment you go from "cool local demo" to "operating system for your company's AI workforce," you hit the same wall every multi-tenant system hits: who can see what, and how do you enforce it when humans aren't in the loop?
Why the orchestration layer can't solve this alone
OpenClaw is excellent at what it does: spawning agents, managing delegation, routing messages across WhatsApp, Telegram, Slack, and email, handling tool calls, and implementing the reasoning loops that let a CEO agent coordinate specialists.
But orchestration frameworks are not authorization systems. They solve the control flow and reasoning problem. They don't solve the data and trust problem.
When Fella's bug-routing sub-agent queries the database, the orchestration layer has already done its job. It routed the task. It spawned the agent. It provided context. What happens next — whether that agent can read rows it shouldn't, modify tables it wasn't meant to touch, or leak data across tenant boundaries — is entirely a function of what the database allows.
And if the database allows everything by default, then every agent inherits the broadest possible permissions. Not because anyone decided that was the right policy. Because nobody configured it otherwise.
This is the pattern we keep seeing: permissions that work by absence rather than by design. No one explicitly granted the VOC bot access to auth tables. But no one explicitly denied it either. And in a system where agents operate autonomously, at speed, at scale — that gap is where breaches live.
The database as trust boundary
This is the thesis Constructive was built around, and multi-agent systems make it more urgent, not less.
When you have one orchestration layer managing sixteen agents, and those agents share a database for memory, task history, credentials, tool outputs, and embeddings, the database becomes the single point where trust can be structurally enforced. Not checked at runtime. Not validated in application code that an LLM generated. Enforced in the schema itself, at creation time, before any agent writes its first row.
Constructive's approach:
Compiled Row-Level Security. RLS policies aren't suggestions you add after deployment. They're compiled and applied when tables are created. They don't drift. They don't get forgotten. They're version-controlled SQL, testable in CI/CD, and deterministic across environments. In a Fella-style hierarchy, this means each sub-agent operates within a constrained database session. The comp-intel bot physically cannot query customer PII — not because application logic prevents it, but because the database won't return the rows.
Native multi-tenancy with org, team, and user hierarchies. Multi-agent systems map naturally to organizational structures. Fella is the top-level role. Each of the sixteen specialists gets a scoped session. If Naman scales to team-wide use — multiple humans, multiple departments, one OpenClaw instance — the isolation model is already in place. You don't build it after things break. It's the starting state.
Policy-aware embeddings and vector search. Agents need memory. Long-term recall, semantic search over past executions, cross-agent knowledge sharing — these are table stakes for any serious multi-agent deployment. But embeddings without access controls are a data exfiltration vector. When Fella queries "what did the marketing agents learn last week?" the vector search should respect the same RLS policies as every other query. Constructive's automated embedding pipelines inherit authorization by default.
Serverless functions that inherit the permission model. Sub-agents don't just read and write data. They execute logic — tool calls, background jobs, scheduled workflows. Constructive extends database-enforced security into a language-agnostic execution layer. Functions written in TypeScript, Python, Rust, or containerized runtimes automatically inherit the same permissions. No separate authorization system to maintain. No drift between what the database allows and what the compute layer assumes.
What this looks like in practice
Take the exact use cases from Aakash's post:
Live knowledge bot — needs secure, shared RAG across a corpus of company knowledge. With Constructive, the vector store inherits RLS. The bot searches semantically, but only within the rows its role is authorized to see.
Automated standups — produce persistent, queryable history. That history contains performance data, blockers, team context. It should be scoped to the team that generated it, not globally readable by every other agent in the hierarchy.
Push-based competitive intelligence — gathers market signals and stores them as embeddings. Isolated per-team vector stores mean the sales team's comp intel doesn't bleed into the engineering team's bug triage context.
VOC reporting — touches customer feedback, which often contains PII or sensitive account details. RLS ensures the VOC bot can aggregate trends without exposing individual records to agents that don't need them.
Auto bug routing — creates auditable task logs. When a regulator or auditor asks "which agent accessed what data, and when," the answer is in the database's permission model — not reconstructed from application logs after the fact.
Each of these use cases works fine in a local SQLite demo. Each of them becomes a liability at company scale without structural access controls.
The integration path is already forming
OpenClaw's community is already pushing Postgres and pgvector upgrades for scaling beyond SQLite. The architectural fit is natural: agent sessions map to database roles. Agent hierarchies map to org/team/user scoping. The skill marketplace's composability mirrors pgpm's modular approach to database schemas — reusable, versioned modules for agent memory, task audit, credential vaults, and more.
This isn't hypothetical. The community has already published a Constructive deployment skill for OpenClaw, installable via npx skills add. Docker-based launchers exist. The wiring is being built in the open.
The real question
The agentic era isn't arriving gradually. It's arriving in architectures — hierarchies of autonomous systems that delegate, persist, and operate without human review at every step.
The orchestration problem is being solved. OpenClaw, LangGraph, CrewAI, AutoGen — there's no shortage of frameworks that can make one agent manage fifteen others.
The trust problem is not solved. And it gets exponentially harder as agent count, autonomy, and data sensitivity increase.
Every team building multi-agent systems will eventually face the same question: where does trust live in this architecture?
If the answer is "in the application code that an LLM generated" or "in the orchestration layer that's optimized for reasoning, not authorization" — that's a design choice with real consequences.
If the answer is "in the database, compiled at creation time, enforced structurally, testable in CI/CD, and inherited by every agent and function that touches the data" — that's a different architecture entirely.
We think the second one is the only one that scales.
Constructive is a secure-by-default Postgres platform for the agentic era. Our open-source ecosystem powers the infrastructure behind platforms like Supabase, Neon, and more — with over 100 million npm downloads. Learn more at constructive.io.